
* 이 글은 <밑바닥부터 시작하는 딥러닝2 (저자: 사이토 고키)> 책을 읽으며 정리한 글입니다.
* 나중에라도 제가 참고하기 위해 정리해 두었으며, 모든 내용을 적은 것이 아닌,
필요하다고 생각되는 부분만 추려서 정리한 것임을 미리 밝힙니다.
목차
- 퍼셉트론 식의 변형
- 활성화 함수(Activation function)
- 3층 신경망
- 출력층(Output Layer)
1. 퍼셉트론 식의 변형
저번 포스트부터 읽어온 분들은, 그래서 인공신경망이 대체 뭔데? 하는 마음으로 이 포스트를 열었을 것이다. 그리고 또 저번 포스트를 착실하게 읽었다면, 왠지 아래의 수식이 눈에 익을 것이다.
$$
y = \begin{cases}
0\ (b + w_1x_1 + w_2x_2 \le 0)\\
1\ (b + w_1x_1 + w_2x_2 > 0)
\end{cases}
$$
그래, 그 식이다. 초등교육과 고등교육 과정을 들먹이며 계속 우려내던 퍼셉트론에 관한 식 최종ver.txt... 하지만 애석하게도 여기에 최최종ver이 하나 더 있다. 위의 식은 다음과 같이도 표현이 가능하다.
$$
\begin{aligned}
y = & h(b + w_1x_1 + w_2x_2)\\[2mm]
& h(x) = \begin{cases}
0\ (x \le 0)\\
1\ (x >0)
\end{cases}
\end{aligned}
$$
즉, 신호가 유효한지 아닌지 판단해주는 $h(x)$ 함수를 따로 세우는 것이다. 식 하나를 둘로 나누는 건데 이게 무슨 대단한 일이라고 요란이야, 라는 생각이 들 수도 있겠다. 바로 여기에서 활성화 함수라는 개념이 등장한다.
2. 활성화 함수(Activation function)
앞서 $h(x)$를 분리해내며 활성화 함수의 등장을 예고했다. 위와 같이 식을 둘로 나눌 때의 가장 큰 매력은, $h(x)$를 슬쩍 다른 것으로 갈아끼울 수도 있다는 데에 있다. 지금까지 우리는 0 초과일 때 1이고, 0 이하일 때 0인 단순한 함수만을 사용해왔다. 이를 그래프로 그리면 아래와 같다.
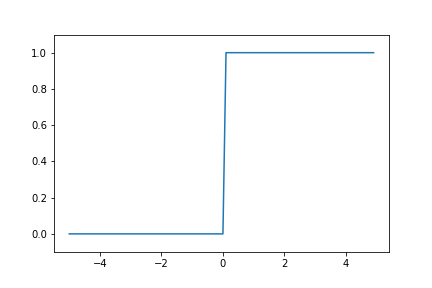
생긴 모양 때문인지, 이것을 계단 함수(step function) 라고 한다.
단층 퍼셉트론에서는 이 계단 함수를 많이 사용하지만, 인공신경망은 여러 이유(그 이유란 것은 앞으로 차차 알아갈 것이다) 때문에 다른 형태의 활성화 함수를 이용한다.
인공신경망을 다루는 데에 있어 필요한 대표적인 세가지 활성화 함수에는 시그모이드, ReLU, tanh 함수가 있다. 스텝 함수와 더불어, 이 세가지 함수에 대한 개략과 모양새를 소개하겠다.
2-(1). 계단 함수(step function)
계단 함수의 식은 익히 봤듯이, 다음과 같다.
$$
h(x) = \begin{cases}
0\ (x \le 0)\\
1\ (x >0)
\end{cases}
$$
이것을 파이썬으로 구현하면 다음과 같다.
def step_function(x):
if x > 0:
return 1
else:
return 0위의 구현은 지극히 단순하게 구현한 것으로, 한 개의 값을 넣으면 한 개의 값을 출력하게 되어있다. 배열을 집어넣어 배열이 한꺼번에 튀어나오게 하여, 대량의 데이터를 빠르게 계산하도록 해보자.
import numpy as np
def step_function(x):
return np.array(x>0, dtype=np.int)위의 코드를 해석하자면, 0 초과인 x에 대해서 True값을, 0 이하인 x에 대해서는 False값을 반환하는 데, dtype=np.int를 넣음으로 True는 1로, False는 0으로 바꿔주는 것이다. 이렇게 단 한줄로 계단 함수가 완성되었다. 그래프의 모양은 위에서 언급했으므로 생략하도록 하겠다.
2-(2). 시그모이드(sigmoid) 함수
시그모이드 함수는 다음과 같다.
$$
h(x) = \frac {1}{1+\exp(-x)}
$$
이를 파이썬으로 구현하면 다음과 같다.
def sigmoid(x):
return 1 / (1 + np.exp(-x))그래프 모양은 다음과 같이 나온다.

시그모이드는 모든 값을 0과 1 사이에 넣어주기 때문에 확률과 같은 형태로 데이터를 변형해준다는 특징이 있다. (참고: 위키백과)
2-(3). ReLU(Rectified Linear Unit) 함수
렐루(ReLU)함수는 스위치와도 같다. ON이 되었을 때는 방해 없이 입력값 그대로를 출력값으로 내보낸다. 반대로 OFF일 때는 출력값이 모두 0이다.
렐루(ReLU) 함수에 대한 식은 다음과 같다.
$$
h(x)=\begin{cases}
x\, (x > 0)\\
0\ (x \le 0)
\end{cases}
$$
즉, 입력이 0을 넘지 않으면 다 신호를 죽이고, 0을 넘으면 입력 그대로를 출력하는 함수이다.
파이썬으로 구현하면 다음과 같다.
def relu(x):
return np.maximum(0, x)위의 코드를 해석하면 다음과 같다. 입력이 들어왔을 때 그 값이 0보다 작으면 x와 0 중에 최대값인 0을 내놓고, 0보다 크면 0과 입력값 중에 최대값인 x를 내놓는 것이다.
그래프는 다음과 같다.
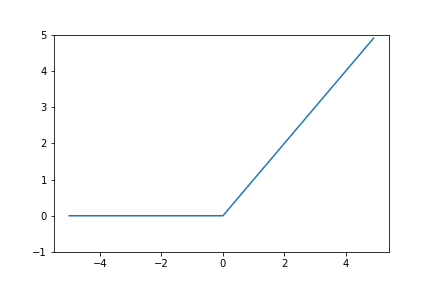
앞선 시그모이드(sigmoid) 함수같은 경우, 값이 0과 1 사이이기 때문에 시그모이드(sigmoid) 함수를 자꾸 지나갈 수록 그 값이 점점 작아져 0에 무한히 가까워지는 현상이 일어날 수 있다. 이를 방지하기 위해 렐루(ReLU) 함수가 등장한다.
2-(4). tanh(Hyperbolic Tangent) 함수
tanh 함수에 대한 식은 아래와 같다.
$$
h(x) = \frac {e^x-e^{-x}}{e^x+e^{-x}}
$$
tanh 함수는 -1에서 1 사이의 값으로 데이터들을 변형시킨다. tanh 함수 역시 넘파이에 내장되어 있어서 한 줄로 구현할 수 있다.
def tanh(x):
return np.tanh(x)tanh 함수를 그래프로 그리면 다음과 같다.

지금까지 4개의 활성화 함수를 살펴 보았다. 물론 이 4개의 함수 말고도 엄청 많은 종류의 활성화 함수가 있다. 조금 더 많은 활성화 함수를 보고싶다면 여기를 참고하도록 하자. (정말 많다...)
3. 3층 신경망
지금까지 우리는 2층 이상 넘어가지 않았다. 이제 신경망의 구현에 필요한 활성화 함수도 배웠겠다, 3층으로 넘어가보도록 하자. 여기서 신경망에서의 계산을 행렬 계산으로 정의하는 것을 주목하며 학습해보도록 하자.
두 개의 입력값 $x_1$, $x_2$를 받아 두 개의 출력값 $y_1$, $y_2$를 내놓는 신경망을 생각해보자. 1층에는 세 개의 노드, 2층에는 두 개의 노드를 놓을 것이다. 편향 $b$도 하나의 노드로 생각하면, 다음과 같이 그려질 것이다.
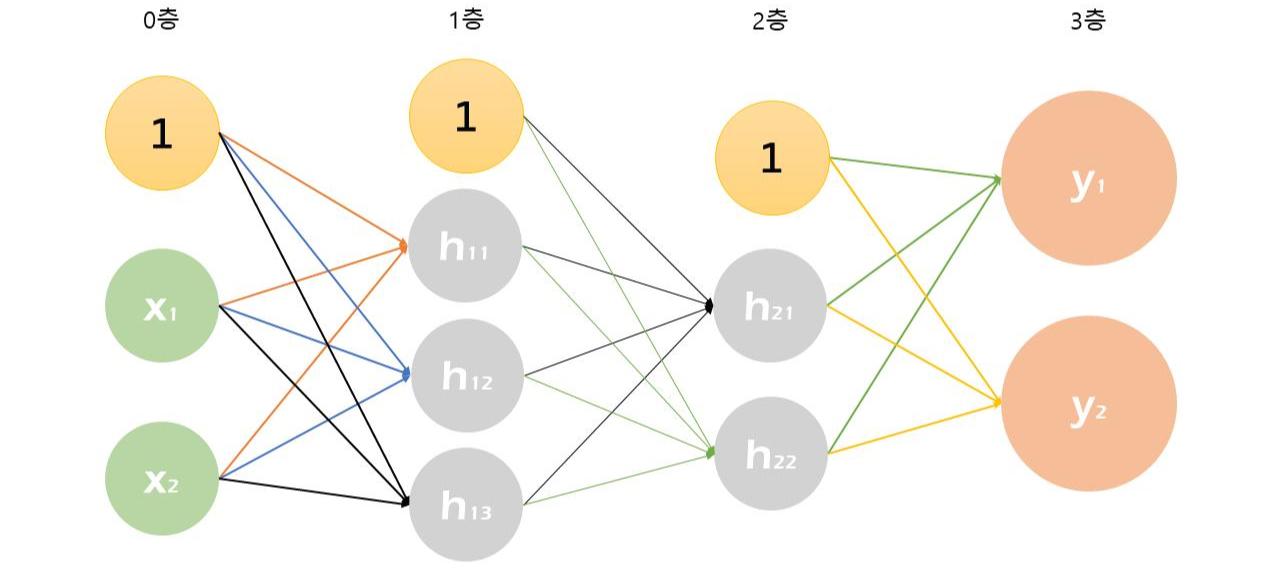
여기서 1을 편향(bias)을 뜻하며, b의 가중치를 갖는다고 해석될 수 있다.
하나의 노드 안에서는 우리가 퍼셉트론을 복습하며 배웠던 식인, 다음과 같은 식이 돌아가고 있다. 앞서 배웠듯이, 활성화 함수를 시그모이드(sigmoid) 함수로 바꿔서 넣어보자.
$$
\begin{aligned}
y = & f(b\cdot 1 + w_1\cdot x_1 + w_2\cdot x_2)\\[2mm]
& f(x) = \mathrm{sigmoid}(x)
\end{aligned}
$$
위의 식을 참고하여 가중치와 편향 값을 임의로 정해 3층 신경망을 구성해보자.
def init_network():
network={}
network['W1'] = np.array([[.1, .3, .5],[.2, .4, .6]]) # 1층에서의 가중치 값 / 모양 = (input_size, hiddn1_size)
network['b1'] = np.array([.1, .2, .3]) # 1층에서의 편향 값 / 모양 = (hidden1_size, )
network['W2'] = np.array([[.1, .4], [.2, .5], [.3, .6]]) # 2층에서의 가중치 값 / 모양 = (hidden1_size,hidden2_size)
network['b2'] = np.array([.1, .2]) # 2층에서의 편향 값 / 모양 = (hidden2_size, )
network['W3'] = np.array([[.1, .3], [.2, .4]]) # 3층에서의 가중치 값 / 모양 = (hidden2_size, output_size)
network['b3'] = np.array([.1, .2]) # 3층에서의 편향 값 / 모양 = (output_size, )
return network
def sigmoid(x):
return 1/(1 + np.exp(-x))
def out_function(x):
return x
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = out_function(a3)
return y
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)init_network()를 통해 가중치와 편향에 임의의 값을 부여한다. sigmoid(x)를 통해 활성화 함수를 정의하고, out_function(x)을 통해 데이터가 어떤 값으로 표현되어야 하는지를 정의한다. 마지막으로 forward(network, x)를 통해 계산 식을 구성하고 실행한다.
4. 출력층(Output Layer)
앞서 3층 신경망을 구성하며 out_function(x)이라는 함수가 있었던 것을 기억할 것이다. 혹자는, '그냥 y=a3이라고 하면 될 것을 왜 저렇게 복잡하게 함수를 하나 거치도록 했을까?'라고 궁금했을 수도 있겠다. 그것에 대한 답이 여기 있다. 사실 바로 앞서 썼던 함수는 입력된 값을 그대로 바로 출력하는, '항등 함수(identity function)'였다. 하지만 출력층에는 그 목적에 따라, 다른 형태로 나타내야 할 필요성이 있다. 예를 들어서, 분류를 하는 문제에서는 0.31682708이나 0.69627909와 같은 숫자는 아무런 의미도 갖지 못할 것이다. 따라서 분류 문제에서는 조금 다른 층을 통과하도록 하는데, 대부분의 분류 문제에서 쓰이는 함수는 소프트맥스(softmax) 이다.
정리를 해보자면, 기계학습 문제에는 회귀(regression) 와 분류(classification) 문제 두 개가 있다. 회귀 문제는, 예를 들자면 키를 보고 몸무게를 추정하는 문제이다. 대부분의 경우 키가 클수록 몸무게도 많이 나갈 것이다. 분류 문제는 어떤 동물 사진을 보고 그 사진이 '고양이'인지, '개'인지를 판단하는 문제이다. 이처럼, 풀고자하는 문제에 따라 다른 출력층(Output Layer)이 쓰인다.
4-(1). 소프트맥스(softmax) 함수란
앞서 언급했듯, 소프트맥스는 분류에 쓰이는 함수이다. '전체 값 중의 특정 값' 형태로 데이터를 변환해주어서, 어떤 값을 '확률'로 볼 수 있는 시각을 제공해준다.

그림에서 보이듯이, 세개의 어떤 실수값을 소프트맥스를 이용해 계산하고 나면 확률 값으로 나온다. (나온 세개의 값을 다 합치면 1이 나온다는 사실을 알 수 있다.) 소프트맥스에 관한 식은 다음과 같다.
$$
y_k = \frac {\exp(a_k)}{\sum_{i=1}^{n}{\exp(a_i)}}
$$
4-(2). 소프트맥스(softmax) 함수 구현 시 유의점
소프트맥스 함수는 지수 함수를 사용한다. 이 말은, 어떤 계산 값의 결과가 엄청나게 커질 수 있다는 뜻이다. 무한대에 가까운 엄청나게 큰 애들끼리 나눗셈을 하면 수치가 매우 불안정해진다. 따라서 분자, 분모에 같은 값을 곱하는 트릭을 사용해서 안정화시키는 방법을 사용한다. 다음과 같이 말이다.
$$
\begin{aligned}
y_k = \frac {\exp(a_k)}{\sum_{i=1}^{n}{\exp(a_i)}} & = \frac {C\exp(a_k)}{C\sum_{i=1}^{n}{\exp(a_i)}}\\[2mm]
& = \frac {\exp(a_k + \log C)}{\sum_{i=1}^{n}{\exp(a_i + \log C)}}\\[2mm]
& = \frac {\exp(a_k + C')}{\sum_{i=1}^{n}{\exp(a_i+C')}}
\end{aligned}
$$
여기서 $C'$에는 어떤 값을 대입하든 상관 없지만, 일반적으로는 입력값 중 최댓값을 넣는다.
이를 바탕으로 파이썬으로 구현하면 다음과 같다.
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 오버플로 방지
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
정리
지금까지 길고 긴 여정동안, 인공신경망의 초석을 다졌다.
다음 포스트에서는 손글씨를 분류하는 작업을 통해 인공신경망의 구체적인 예시를 학습해보겠다.
'AI Archive > Anthology' 카테고리의 다른 글
| [밑러닝] 인공신경망의 학습 지표, 손실함수(loss function) (0) | 2020.03.17 |
|---|---|
| [밑러닝] 손글씨 숫자 인식으로 해보는 간단한 인공신경망 예측(feat. MNIST 데이터셋) (0) | 2020.03.17 |
| [밑러닝] XOR 문제의 해결, 층 쌓기 (0) | 2020.03.11 |
| [밑러닝] 퍼셉트론(perceptron), 인공신경망의 기원 (0) | 2020.03.11 |
| [밑러닝] 1.6 matplotlib, 파이썬의 시각화 툴 (0) | 2020.02.28 |