
이 글은 논문 Finding the Optimal Vocabulary Size for Neural Machine Translation을 읽고 리뷰한 글입니다.
0. 들어가며
인공지능을 만지다 보면 하이퍼파라미터에 대한 의문이 들 때가 있다.
도대체 이건 왜 이 숫자여야 하는가, 라는 원론적이고 당연한 물음이다.
하지만 돌아오는 대답은 늘,
"이렇게 하면 좋다더라"
"저렇게 하면 적당하다더라" 정도였다.
실제로 실무에서 하이퍼파라미터를 선정할 때도, 경험이나 trial-and-error로 나온 결론에 의존해서 선정할 때가 많았다.
하지만 다루는 데이터의 성격도, 사이즈도 다 다른데, 언제까지나 '좋다더라' 식으로 선정된 숫자가 베스트일 리는 없다.
기계번역기의 하이퍼파라미터에서 그 숫자에 제일 의문이 많이 들었던 것은 보캡 사이즈였다.
단순하게 생각하면, 보캡이 크면 클수록 좋은 거 아냐? 라고 생각할 수 있다.
예측 시 참고할 수 있는 단어의 숫자가 많아진다는 것이니까.
하지만 곰곰이 생각해보면 (극단적으로는) 빈도가 하나밖에 없는 토큰일 경우 임베딩이 제대로 되지도 않을 것이다.
즉, 빈도수가 낮은 토큰은 차라리 잘라내는 게 좋다.
그렇다면, 그렇다기에는 기계번역기는 해괴망측한 토큰까지 다 제대로 번역을 해내야 하는 걸...?🥲
모든 토큰을 살뜰히 챙겨서 번역을 수행해야하는 비극적인 NMT의 운명에도 불구하고,
일단은 그나마 성능이 가장 좋을 최적의 보캡 사이즈를 선정하는 게 중요하다.
다행히 선행 연구를 발견할 수 있었다. 2020년, EMNLP에 제출된 논문이다.
현재(2022. 04. 04)까지 15회 인용되었고, Southern California 대학의 Information Scences Institute에 있는 Thamme Gowda와 Jonathan May에 의해 작성되었다.
이 논문에 대한 리뷰 글이,
적정한 보캡사이즈를 찾아 오늘도 GPU를 아낌없이 돌리는 NMT 연구자들에게 부디 도움이 되길 바란다.
Abstract
NMT는 일종의 분류기(classifier)로 볼 수 있다.
타겟언어의 토큰 하나하나가 하나의 클래스(하나의 라벨)로 가정될 수 있는 것이다.
일반적으로 분류기는 예측하려는 클래스가 균일할 수록 더 훈련이 잘 된다.
하지만 자연어는 그 특성상 모든 단어(토큰)의 빈도가 동일하지 않다.
특히 지프 분포(Zipfian distribution)를 가지는 양상을 띤다.
이번 논문에서는,
- 다양한 언어와 데이터 사이즈에서 다양한 vocabulary size가 NMT 성능에 미치는 영향을 분석하고,
- 특정 사이즈가 왜 좋은지에 대해 밝힌다.
1. Introduction
용어 정의
클래스 불균형(Class imbalance)
: 하나 이상의 클래스들이 (대략적으로라도) 데이터 내 빈도가 일정하지 않을 때를 이르는 말
: 클래스 불균형 문제는 분류기가 쓰이는 다양한 태스크에서 연구되었으나, NLP 분야에서는 아직 연구가 활발하지 않다.
: 자연어는 지프 분포를 따르고, 이러한 성질 때문에 classifier-based NLG system에서는 두가지 문제점을 보인다.
지프 분포(Zipfian distribution/ Zipf's law)
지프 분포란, 어떠한 자연어 말뭉치에 나타나는 단어(토큰)들을 그 사용 빈도가 높은 순서대로 나열했을 때, 모든 단어의 사용 빈도는 해당 단어의 순위에 반비례한다는 것이다. 예를 들어, 가장 사용 빈도가 높은 영어 정관사 'the'가 전체 문서에서 7%의 빈도를 차지한다면, 두 번째로 사용 빈도가 높은 단어인 'of'는 약 3.5%의 빈도를 차지한다는 것이다.
이로 인해 단어의 등장 빈도수와 순위로 로그 스케일 그래프를 그리면 직선 모양에 가깝게 나타난다고 한다.
지프 분포가 야기하는 두가지 문제점
- Unseen Vocabulary
: 트레인 셋에 없는 유형의 클래스가 등장할 가능성이 높다. - Imabalanced Classes - a few extremely frequent types & many infrequent types
: 분류기가 사용된 것과 다른 분야의 도메인에서는 예기치 못한 편향(undesired biases)과 심각한 기능 저하(severe performance degradation)가 나타난다.
=> 이를 해결하기 위해 subwords 개념이 도입되었고, 현재 BPE(Byte Pair Endocing) 방식이 널리 사용된다.
==> BPE의 등장으로 'merge operations'라는 하이퍼파라미터가 등장하게 되고, 이것으로 vocab size를 조절할 수 있다. 이것은 trial-and-error를 통해 선정한다.
문제점 제시
이번 논문을 통해, 두가지 질문에 답을 하고자 한다.
- What value of BPE vocabulary size is best for NMT?
- Why that value?
위의 두가지 질문은 결국 하나의 질문으로 이어진다. 'What is the impact of Zipfian imbalance on classifier-based NLG?'
개괄
섹션2에서는 NMT 구조에 대해 간략하게 살펴본다.
이 논문에서는 NMT를 크게 두가지 요소(classifier & autoregressor)를 가진 객체로 본다.
2.1에서는 classifier에 대해 살펴보고, 2.2에서는 autoregressor에 대해 살펴본다. 마지막으로 2.3에서는 어떻게 vocab size가 앞서 언급한 두 개의 요소에 어떤 관련이 있는지를 살펴본다.
섹션3에서는 실험 조건들을, 섹션4에서는 그에 따른 결과 분석을 제시한다. 동시에 왜 특정 사이즈가 좋은지에 대해 증거와 함께 설명을 제공한다.
섹션 5에서는 클래스 불균형의 영향에 대해 알아보고, 특히 빈도수 기반한 클래스 간의 차이점을 알아본다.
섹션 6에서는 관련 연구를, 섹션 7에서는 BPE 하이퍼 파라미터를 선택하기 위한 경험적인 방법론을 추천한다.
2. Classifier based NLG
기계번역은 보통, 시퀀스 $x = x_1x_2x_3...x_m$를 시퀀스 $y = y_1y_2y_3...y_n$으로 변환하는 업무로 취급된다. (where $x$ is in source language X and y is in target language Y)
물론 NMT의 구조는 다양하다. 하지만 이 많은 구조들에게서 공통적으로 찾아볼 수 있는 특징이 두가지 있다.
첫번째는, (1)출발 언어의 시퀀스와 (2)도착 언어의 $t-1$번째까지의 값이 주어졌을 때,
$t$번째에 특정 값 $y_t$가 등장할 확률의 합을 최대화한다는 점이다.
($\prod_{t=1}^{n}P(y_t|y_{<t}, x_{1:m})$ for pairs $(x_{1:m}, y_{1:n})$ sampled from a parallel dataset)
두번째는, 공통적으로 인코더-디코더 구조를 취하고 있다는 것이다. 여기서는 인코더, 디코더라는 용어 대신 autoregressor(R)와 classifier(C)로 NMT의 구조를 재조명한다.
Autoregressor, R 부분에는 다양한 신경망 구조가 사용될 수 있다: RNN, LSTM, GRU, CNN, Transformer
R 부분에서는 특정 타입 스텝 $t$에서 입력문(input context) $y_{<t},x_{1:m}$을 은닉 상태 벡터(hidden state vector) $h_t = R(y_{<t}, x_{1:m})$로 변환한다.
한편 C 부분에서는 모든 구조에서 비슷한 양상을 띤다. h_t를 분포 $P(y_j|h_t)∀y_j ∈ V_Y$에 매핑시키는 것이다. (where $V_Y$ is the vocabulary of $Y$)
흔히 머신러닝에서는 분류기에 대한 입력값은 수작업으로 작성되거나 자동으로 추출된 feature가 들어가게 되는데,
기계번역에서의 분류기 C는 R에서 내놓은 feature를 받는다. 즉, R은 C 입장으로 봤을 때는 automatic feature extractor로써 기능하는 것이다.
2.1 Balanced Classes for Token Classifier
클래스 빈도 불균형은 필연적으로 편향을 발생시킨다.
이는 분류 작업이 어떻게 학습되는가를 생각해보면 금방 알 수 있다.
애초에 분류기라는 것이 등장 빈도에 초점을 맞추게끔 학습된다.
따라서 빈도수가 낮은 클래스에 대해서 성능이 형편없이 떨어지게 된다.
이에 따라 _domain mismatch_가 발생했을 경우, (예를 들어 트레인 셋과 테스트 셋의 분포가 일치하지 않을 때) 모델의 성능은 급격하게 감소한다.
각각의 클래스가 독립적인 작업에서는 빈도수가 낮은 클래스를 up-sampling 하거나 빈도수가 높은 클래스를 down-sampling 하면 될 일이다.
하지만 NMT에서는 각각의 클래스가 서로 연관되어 있고 문맥 안에 들어가 있기 때문에, 동일한 방법을 취할 수 없다.
대신 서브워드 분할의 수준을 변경해가며 밸런싱 목표를 달성할 수 있다. (Sennrich et al., 2016)
Quantification of Zipfian Imbalance
지프 불균형을 측정하기 위해 두가지 통계적 방법이 존재한다.
- Divergence (D) from balanced (uniform) distribution.
$$D = \frac{1}{2} \sum_{i=1}^{K}|p_i - \frac {1}{K}|$$
$$0\leq D\leq 1$$
imbalance measure $D$ on $K$ class distributions where $p_i$, is the observed probability of class $i$ in the training data
: $D$가 데이터 분포가 균형적이라는 뜻이다. 클래스 간의 균형이 맞을 수록 거의 같은 빈도수를 보이기 때문이다. - Frequence at 95th% Class Rank ($F_{95}$)
: 빈도수로 나열했을 때, 가장 빈번한 클래스의 95번째 백분위수에서 가장 낮은 빈도로 정의된다.
: $F_{95}$가 높을수록 이상적이다.
2.2 Shorter Sequences for Autoregressor
: 시퀀스의 길이에 비례해서 에러는 축적된다.
: 이를 경감시키기 위해 beam search 등의 방법이 시도되었다. (Koehn and Knowles, 2017)
: 여기에서는 Mean Sequence Length, $\mu$를 계산함으로 시퀀스 길이를 줄인다.
$$\mu = \frac{1}{N} \sum_{i=1}{N}|y^{(i)}|$$
(where $y^{(i)} is the $i$th sequence in the training corpus of $N$ sequences.)
: $\mu$ 가 작을수록 이상적
2.3 Choosing the Vocabulary Size Systematically
: BPE 방식을 이용할 경우
Effect of BPE on $\mu$
: simple white-space segmentation에 비해 $\mu$는 상승, 시퀀스의 길이는 늘어남
: character segmentatiion에 비해 $\mu$는 하락, 시퀀스의 길이는 짧아짐
Effect of BPE on $F_{95}$ and $D$
: 자주 등장하는 subwords는 붙이고 rare word는 (상대적으로 빈번한) subword로 쪼개며, 클래스의 분포에 영향을 준다.
Relation between number of BPE merges and both $D$ and $\mu$

: $D$가 낮을 수록 C에 좋지만, 같은 지점에서 $\mu$는 상당히 높은 값을 가지고 있고, 이는 R에 적합하지 않다.
: 따라서 C와 R 사이에 적정한 정도의 타협점을 찾는 것이 중요하다.
: 하지만 이 '적정한 정도'를 어떻게 찾는단 말인가?
3. Experimental Setup
: 저자는 Transformer 모델을 이용해 네 개의 서로 다른 도착 언어와 다양한 데이터 사이즈를 준비해서 실험적으로 찾아본다.
3.1 Datasets
논문 저자가 준비한 언어쌍은 다음과 같다.
- 영어 $\to$ 독일어 (News Translation task of WMT2019)
- 독일어 $\to$ 영어 (News Translation task of WMT2019)
- 영어 $\to$ 힌디어 (IIT Bombay Hindi-English parallel corpus v1.5)
- 영어 $\to$ 리투아니아어 (News Translation task of WMT2019)
또한 데이터 사이즈에 따른 영향을 분석하기 위해 다음의 언어쌍에 대해 무작위 추출을 진행해 작은 데이터셋을 생성한다. - 영어 $\to$ 독일어
- 영어 $\to$ 힌디어
영어, 독일어, 리투아니아어로는 SacreMoses를 이용해 토크나이징 되었으며, 힌디어는 IndicNlpLibrary로 토크나이징을 진행했다.
약간의 전처리 과정을 거쳤는데, 상대 문장의 길이보다 다섯배가 넘으면 제외했다. 또한 URL이 포함된 모든 문장쌍을 제거했다.
3.2 Hyperparameters
configurations
- # of encoder layers: 6
- # of decoder layer: 6
- # of attention heads: 8
- # of hidden vector units: 512
- feed forward intermediate size: 2048
- activation: GELU
- label smoothing: 0.1
- dropout rate: 0.1
- optimizer: Adam
- warm up: 16K steps
- decay rage: recommended for training Transformer models
- mini-batch size
: 6K tokens for 30K-sentence datasets
: 12K tokens for 0.5M-sentence datasets
: 24K for the remaining larger datasets
$\leftarrow$ 비슷한 길이의 시퀀스로 구성 (패딩 토큰의 수를 줄이기 위해) - early stop: True (All models are trained until no improvement in validation loss is observes)
- patience: 10
- validate: 1K steps
- maximum length: 512 tokens (after BPE)
- (To decode, average the last 10 check-points)
- beam size: 4
- length penalty: 0.6
- seperately learn source and target vocabularies
: 따라서 인코더와 디코더 간의 weight sharing도 없음
: 그러나 디코더 인풋과 분류기 클래스 임베딩간의 sharing은 있음
envirionment
- PyTorch
- NVIDIA P100 & V100
4. Results and Analysis
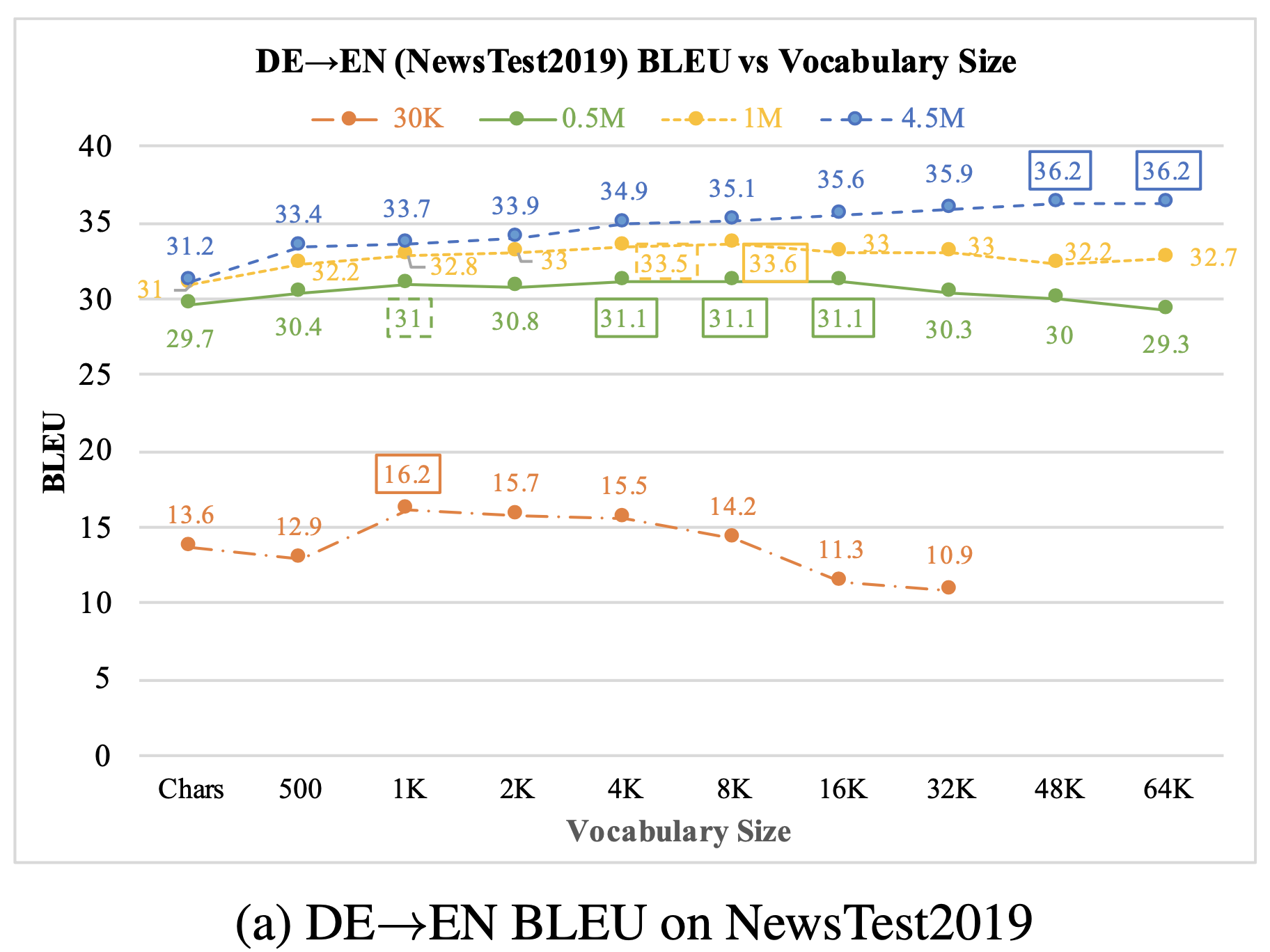

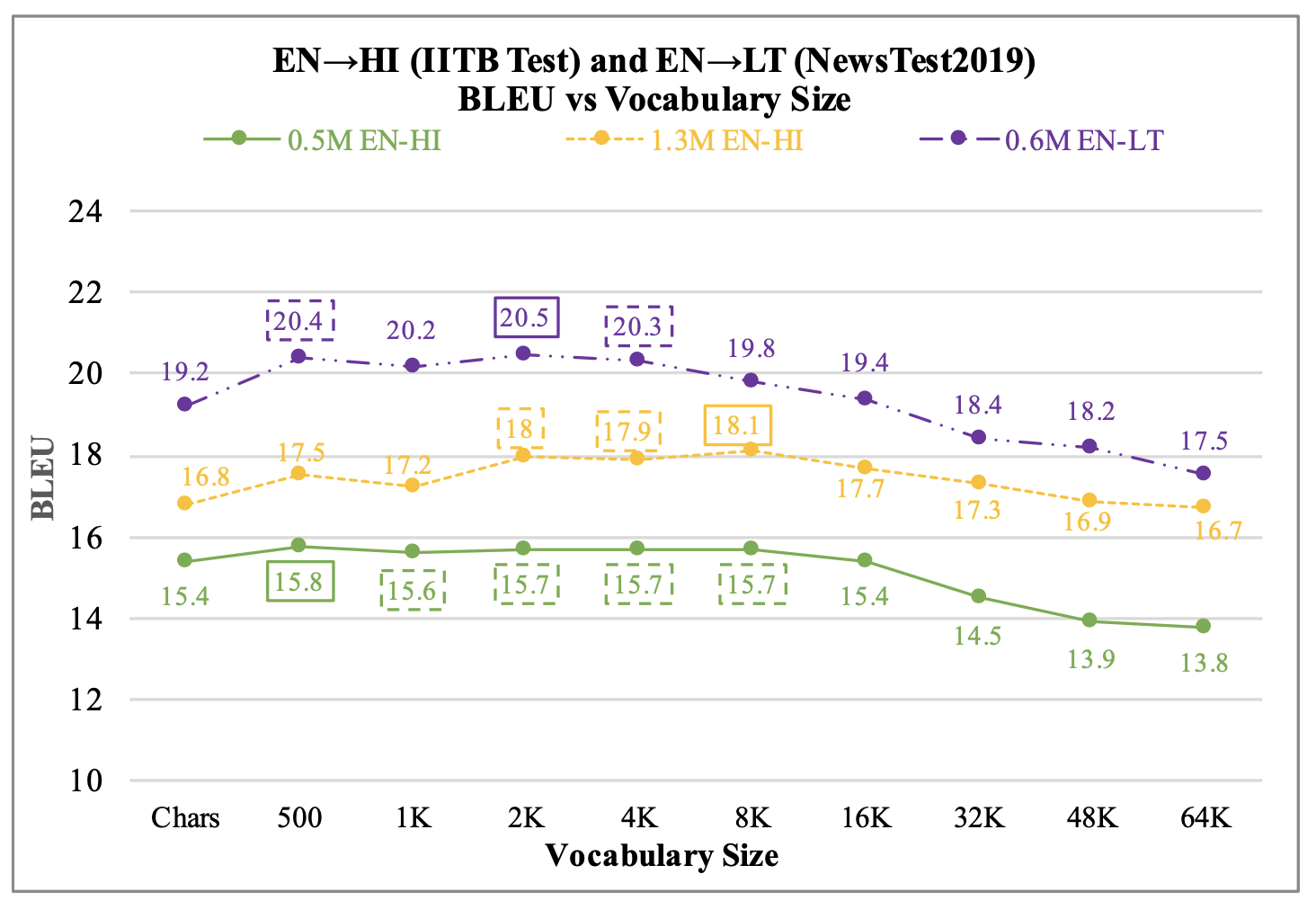
결과는 다음과 같은 점들을 시사한다.
- character set 크기 정도로 작은 vocab size는 좋은 점수를 내지 못한다.
- 32K보다 큰 vocab size는 데이터 셋이 4.5M 규모 정도로 크지 않은 이상 좋은 점수를 내지 못한다.
- vocab size에 따른 BLEU 점수는 산 모양의 그래프를 그린다.
- 데이터셋이 커질수록, BLEU가 최고점을 내는 vocab size는 점차 오른쪽으로 이동한다. (그러나 대략적인 양상일 뿐, 정확하게 예측할 수는 없다)
위의 결과 그래프들을 통해 적정한 vocab size가 어느 정도인지는 알 수 있다.
남은 질문은 왜에 대한 것이다.
앞서 우리는 불균형의 정도를 측정하기 위해 $\mu$와 $D$, $F_{95}$와 같은 통계치들을 언급했다.
이를 연관시키면 다음과 같은 시사점을 얻을 수 있다.
- 작은 vocab size
: 상대적으로 큰 $F_{95}$를 갖는다. (C에 우호적)
: 더 큰 $\mu$ 값을 갖기 때문에 R의 성능을 떨어트림 - 32K 이상의 큰 vocab size
: 상대적으로 작은 $\mu$ 값을 갖기 때문에 R의 성능을 올림
: 상대적으로 작은 $F_{95}$를 갖기 때문에 C의 성능을 떨어트림
: 상대적으로 높은 $D$ 값을 갖기 때문에 C의 성능을 떨어트림
: 큰 데이터셋일 수록 다양한 training example이 있기 때문에, $F_{95}$ 값은 커질 수밖에 없음 - 30K ~ 1.3M의 데이터 사이즈에서:
: vocab sizesms 8K가 가장 이상적이다.
: 이는 휴리스틱한 방법으로 행해졌으며, 여기서 $\mu$는 작고 $F_{95}$는 약 100 이상이다.
BLEU 점수는 오히려 아주 큰 vocab size에서 툭 떨어지는데, $\mu$는 낮고(favorably) $D$는 높기(unfavorably) 때문이다.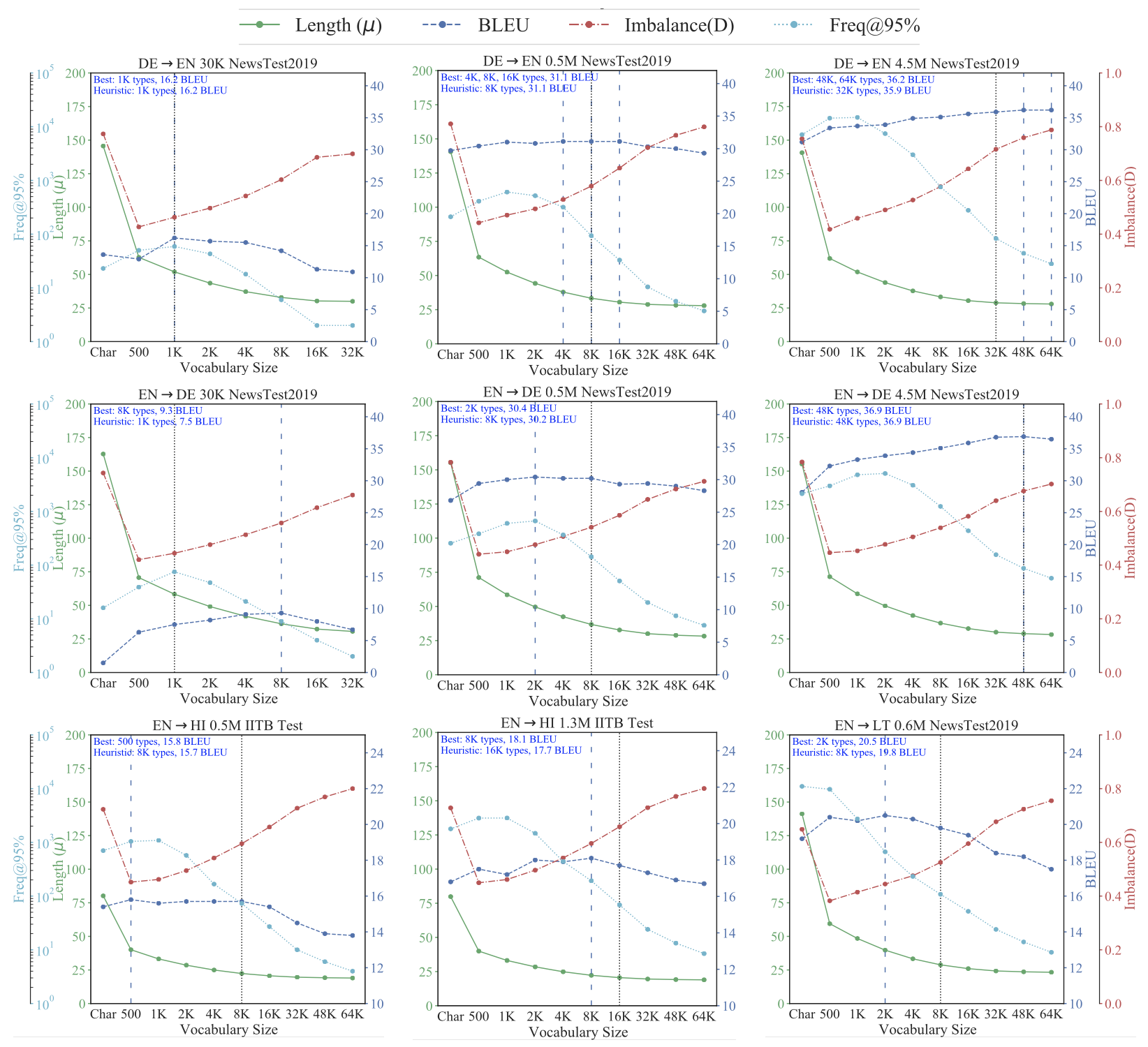
7. Conclusion
이번 논문을 통해, 왜 NLG에 BPE vocabulary 방식이 효과적인지에 대해 살펴봤다.
Transformer NMT를 위해 저자가 추천하는 바는 다음과 같다.
Use the largest possible BPE vocabulary such that at least 95% of classes have 100 or more examples in training
'AI Archive > Periodicals' 카테고리의 다른 글
| 🥇 이주의 ML 논문 (2023-02-20 ~ 2023-02-26) (0) | 2023.12.06 |
|---|---|
| 🥇 이주의 ML 논문 (2023-02-13 ~ 2023-02-19) (0) | 2023.11.30 |
| 🥇 이주의 ML 논문 (2023-02-06 ~ 2023-02-12) (1) | 2023.11.30 |
| 🥇 이주의 ML 논문 (2023-01-30 ~ 2023-02-05) (1) | 2023.11.13 |
| 🥇 이주의 ML 논문 (2023-01-23 ~ 2023-01-29) (1) | 2023.11.13 |