
목차
- 텍스트 분류란
- 멀티클래스 텍스트 분류(Multi-class text classification)
- 멀티틀래스 텍스트 분류를 시행하는 여러가지 모델들
1. 텍스트 분류란
친구와 대화 중, 다음과 같은 문장을 당신이 들었다고 해보자.
"그 영화는 특출난 구석이 어디 하나 없는 밋밋한 스토리였어."
그러면 당신은 친구가 그 영화에 대해 부정적인 평가를 내리고 있다고 생각할 것이다. 그러니까, 방금 당신은 이 텍스트가 '긍정적'인지, '부정적'인지 분류했다는 것이다.
분류는 긍정/부정 뿐만 아니라 다양한 분야에서 이루어진다.
당신은 문서를 분류하며 쓸모에 따라 분류하여 쓸모 없는 것은 폐기한다. 쓸모가 있는 문서는 A프로젝트에 관련된 건지, B프로젝트에 관련된 것인지 분류한다. 이 모든 것이 '텍스트 분류'이다. 즉, 특정 텍스트가 어느 카테고리에 속하는 지 정하는 것을 텍스트 분류라고 한다.
2. Multi-class text classification
앞서 언급했듯이, 리뷰의 긍정/부정을 판단하는 것도 텍스트 분류이지만, 그 리뷰가 카메라에 관한 것인지, 자동차에 관한 것인지, 아니면 노트북에 관한 것인지 판단하는 것 또한 텍스트 분류이다. 이렇게 판단할 카테고리가 둘 밖에 없는 분류를 이진분류(binary classification)이라고 하고 카테고리가 2 초과인 경우를 multi-class 텍스트 분류라고 한다.
3. 멀티클래스 텍스트 분류를 시행하는 여러가지 모델들
(1) 선형회귀(Logistic Regression)
선형회귀란, 종속 변수 y와 한 개 이상의 독립 변수 X와의 선형 상관 관계를 모델링하는 기법이다. (출처: 위키피디아)
선형대수학을 배우지 않았다면 이게 뭔소리인가, 싶을 것이다. 다음과 같은 식을 보면 조금 더 이해가 빠를 것이다.
$$
y=ax+b
$$
우리는 다년간의 경험을 통해 y가 x가 변함에 따라 변한다는 사실을 알 수 있다. 즉, y는 x에 대해 '종속적'이다. 이게 인정이 된다면 다음의 식으로 넘어가보자.
$$
y=a_1x_1+a_2x_2+b
$$
$x_1$과 $x_2$에 의해서 $y$가 변할 것이라고 집작할 수 있다. 여기서 $x_1$과 $x_2$는 서로 영향을 받지 않는 '독립 변수'일 때, $a_1$과 $a_2$, $b$ 등의 값을 최대한 맞추는 게 '선형 상관 관계를 모델링하는 것' 이다.
다시 논점으로 돌아와보자. 우리는 텍스트를 여러개의 클래스로 분류해야 한다. 물론 처음부터 이건 1번, 저건 2번, 저쪽 3번 등으로 한번에 분류할 수 있다면야 너무 좋겠지만, 이런 식으로 분류할 수도 있다. 1번과 1번이 아닌 것, 2번과 2번이 아닌 것, 3번과 3번이 아닌 것 등.
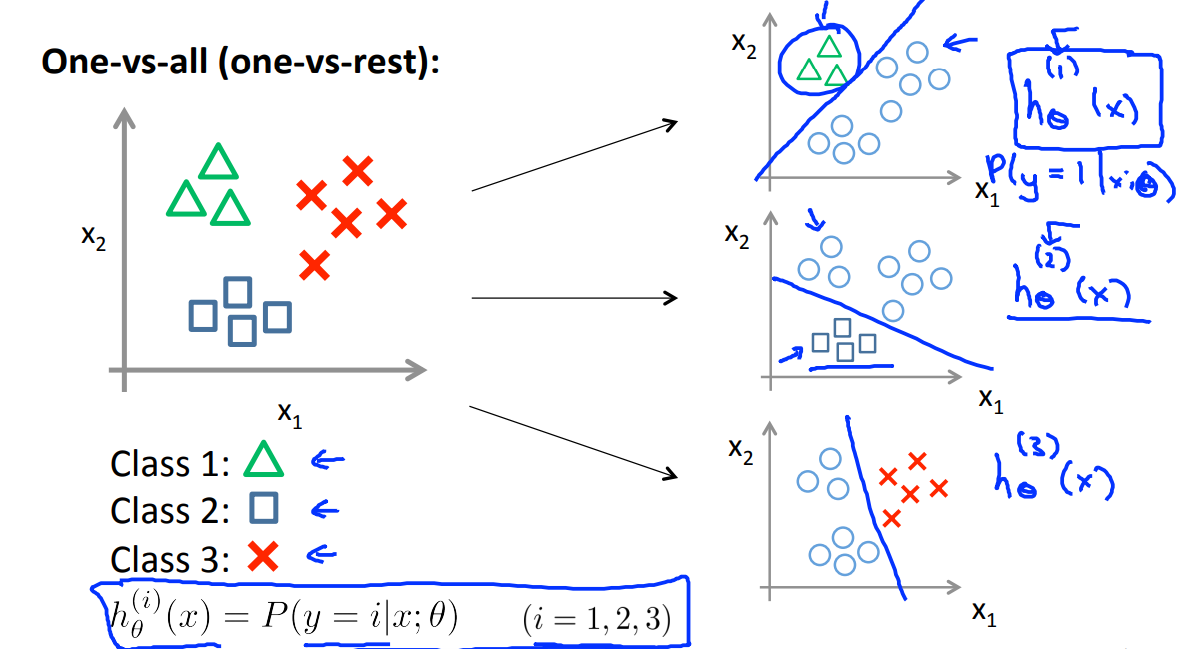
(이미지 출처: Andrew Ng)
$$
h_{ \theta }^{ (i) } (x) = P(y=i|x;\theta)
$$
위의 공식으로 생각해보면, 각 i번째 class에 따른 각각의 확률이 구해질 것이다. 그 중 가장 큰 확률을 가지는 것을 선택하는 것이다.
(2) 랜덤포레스트(RandomForestClassifier)
랜덤포레스트는 의사결정나무(decision tree)의 앙상블(ensemble) 모델이다.
이것이 무슨 말인고 하니, 의사결정나무 모델을 여러개 이용하여 학습하는 모델이라는 뜻이다.(나무(decision tree) 여러개라 숲(forest)이라고 한단다ㅋㅋ)
어떻게 이용하는고 하니, 배깅(bagging) 을 이용한다.
배깅(bagging) 은 bootstrap aggregationg의 약자라고 한다.(어떻게 줄이면 배깅이 되지?)
부트스트랩(bootstrap) 을 통해 조금씩 다른 훈련 데이터에 대해 훈련된 기초 분류기(base learner)들을 결합(aggregating) 시키는 방법이다(부트스트랩이란, 주어진 훈련 데이터에서 중복을 허용하여 원 데이터셋과 같은 크기의 데이터셋을 만드는 과정을 말한다).
배깅(bagging)을 통해 랜덤 포레스트를 훈련시키는 과정은 다음과 같은 세 단계로 진행된다.
- 부트스트랩 방법을 통해 T개의 훈련 데이터셋을 생성한다.
- T개의 기초 분류기(트리)들을 훈련시킨다.
- 기초분류기(트리)들을 하나의 분류기(랜덤포레스트)로 결합한다(평균 또는 과반수투표 방식 이용).
(참고: 위키피디아)
(3) 다항식 나이브 베이즈 분류기(Multinomial Naive Bayes classifier)
나이브 베이즈는 각각의 특성들이 독립적이라고 가정하는 조건부 확률 모델이다.
각각의 특성이 실제로 독립적이지 않을 수 있음에도 불구하고 독립적이라고 퉁쳐버리기 때문에 'naive'가 붙었다고 한다. 하지만 'naive'라는 수식어에 어울리지 않게 분류 모델에서 꽤 좋은 성능을 보인다. (전처리만 잘 하면 서포트 벡터 머신 모델을 넘어서기도 한다는데...)
'각각의 특성들이 독립적'이라고 가정하는 것의 예시를 들어보자면, 다음과 같다. 특정 과일을 사과로 분류 가능하게 하는 특성들(둥글다, 빨갛다, 지름 10cm 내외)은 나이브 베이즈 분류기에서 특성들 사이에서 발생할 수 있는 연관성이 없음을 가정하고, 각각의 특성들이 특정 과일이 사과일 확률에 독립적으로 기여하는 것으로 간주하는 것이다. (예시 출처 : 위키피디아)
(4) 선형 서포트 벡터 머신 분류기(Linear Support Vector Classification)
데이터를 사상된 공간에서 표현했을 떼, 데이터 경계 사이에 선을 그어 가장 큰 폭을 가진 경계를 찾는 알고리즘이다. (출처 : 위키피디아)

정리
멀티클래스 텍스트 분류를 할 수 있는 다양한 머신러닝 모델과 그 개념을 간략히 살펴보았다.
다음 포스트에서는 코드를 이용하여 실제로 머신러닝을 해보는 실습 코드를 게시할 예정이다.
'Task Synopsis' 카테고리의 다른 글
| NER 개론과 NER 데이터셋 모음 (한국어 개체명인식 포함) (0) | 2020.10.26 |
|---|